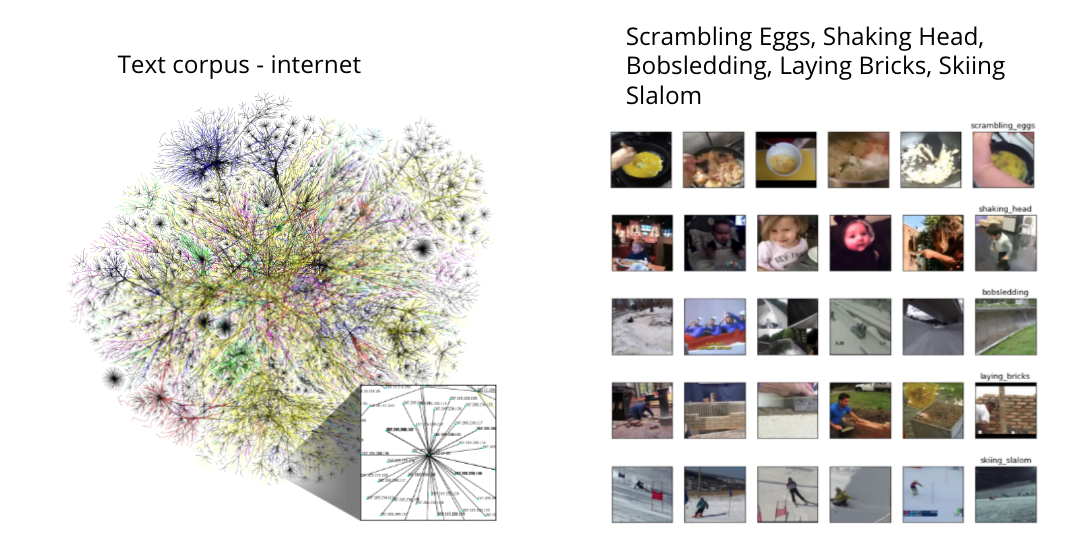
Extending CLIP model to Video Retrieval and Action Recognition
Video
Website
https://feedforward.github.io/blog/extending-CLIP-model-to-video-retrieval-action-recognition/
Introduction
- Content Based Video Retrieval [egs: YouTube] is desirable because searches that rely purely on metadata are dependent on annotation quality and completeness. The presented architecture provides an efficient way of Text based Video Retrieval.
- Also, our work is an extension of CLIP Model Action Recognition [RN50x16], where they have used Mid-frame level approach to get an accuracy of 53.4%, while our method gives an improvement of 83.9% [LSTM] and 85.5% [Transformer] comparing to the SOTA on Kinetics 400 dataset 84.8%.
Motivation
- State of the art computer vision methods are usually structured for a fixed set of output categories or a fixed training data distribution on which the model is trained on.
- This imposes a restricted form of supervision on learning. This restriction indicates that the model is only going to recognize and classify into one of the output classes on which it has learned on or on which it has been trained on. This form of restricted supervision does not prove to be helpful in a real world scenario wherein there could be visual concepts from all sorts of classes on which the model has not been trained on previously.
- Thus, the restricted form of supervision can often limit the generality and usability of the SOTA methods for performing well on other visual concepts. In such a scenario, in order to learn new visual concepts, some form of context can help the model to perform a valid inference at test time and thus learn new visual concepts simultaneously with some help from the context information. With respect to context, zero-shot transfer, natural language supervision and multimodal learning are capable of providing this extra information or context required for the model to learn from and to accurately infer from.
- Open set recognition also proves to be helpful and has been proven to work well with real life examples or scenarios. In open set recognition, incomplete knowledge of the world is present at training time and unknown classes can be submitted to an algorithm during testing. Open set recognition handles these unknown and unseen classes of images efficiently at test time based on certain statistical modelling. We aim to explore more into the Open set recognition approach through our project.
Related Works
Open set
- Deep neural networks have made breakthroughs in a wide range of visual understanding tasks. A typical challenge that hinders their real-world applications is that unknown samples may be fed into the system during the inference phase, but traditional deep neural networks or SOTA computer vision methods will wrongly recognize these unknown samples as one of the known classes. Open set recognition (OSR) is a potential solution to overcome this problem, where the open set classifier should have the flexibility to handle unknown samples and meanwhile maintain high classification accuracy in known classes.
- Consequently, there has been a lot of relevant prior work in this area. Open Set Recognition with Conditional Probabilistic Generative Models [2] proposes an open set classifier which has the flexibility to reject unknown samples posed to the model at test time. In this paper, a novel framework, called Conditional Probabilistic Generative Models (CPGM), for open set recognition is proposed. The core insight of this work is to add discriminative information into the probabilistic generative models, such that the proposed models can not only detect unknown samples but also classify known classes by forcing different latent features to approximate conditional Gaussian distributions.
- Unified Probabilistic Deep Continual Learning through Generative Replay and Open Set Recognition [3] introduces a probabilistic approach to unify open set recognition with the prevention of catastrophic forgetting in deep continual learning, based on variational Bayesian inference. In order to successfully distinguish unseen unknown data from trained known tasks, the paper proposes to bound the class specific approximate posterior by fitting regions of high density on the basis of correctly classified data points.
-
These bounds are further used to significantly alleviate catastrophic forgetting by avoiding samples from low density areas in generative replay. There is much more prior work which involves rejecting or avoiding the unseen or unknown input samples (that are out of the training data distribution or are from a different output class category) at inference time.
- We aim to propose an approach where we perform an Open Set Recognition (OSR) on the unknown or unseen samples but instead of avoiding or rejecting them, we find a way to automatically handle these samples at the inference time. In order to explore this approach more in the open set conditions, we also aim to perform experiments for Video Retrieval from textual input using an image based CLIP model, but on a Video input dataset.
Image retrieval
- The neural network will be trained on text and visual embedding pairs to make it learn a mapping between text and corresponding images. Based on a supervised learning approach, labels, Image and text embedding will be used to match the unseen text data examples to a corresponding image.
- Likewise, we will achieve Image retrieval.
Video based retrieval
- Action recognition is one of the actively researched areas in computer vision. This has led to collection of large sized datasets like kinetics, something-something , AVA etc.
- Most of the work is focused on classifying the actions given temporal and spatial localized clips as an input. A different stream of research that works on non localized input is also being explored. This works by first generating proposals from the input videos and later classifying the proposals.
- Our work focuses on a different way of exploring video understanding, by looking at video as a continuous path in an image embedding space.
Approach
- NLP models are usually trained on all the available text on the internet, we want to take advantage of this for open set video retrieval.
- We do this by projecting videos into an visual embedding, which lie in the same joint embedding space as of text, Following an approach similar to what CLIP did for images.
- We first extend the this clip image based model to videos. Given a video our approach projects it into the joint embedding space. We evaluate the quality of this model using action recognition on kinetics.
- Then we remap the video classification model into retrieval setup. Given a textual query, our setup retrieves all the videos in the video database that match the textual query.
Baseline
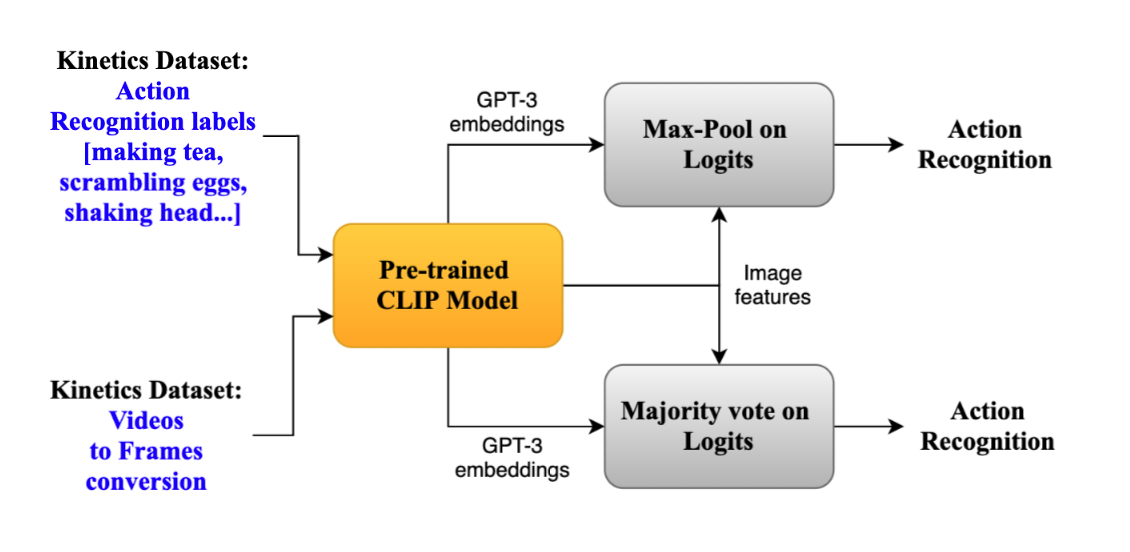
- Towards the first contribution of converting image based CLIP to video classification. We establish the following baselines
- In first visual embeddings are extracted individually for the frames, followed by max pooling.
- In second each image is individually classified, followed by maj vote to make the final prediction.
Temproal fused using LSTM
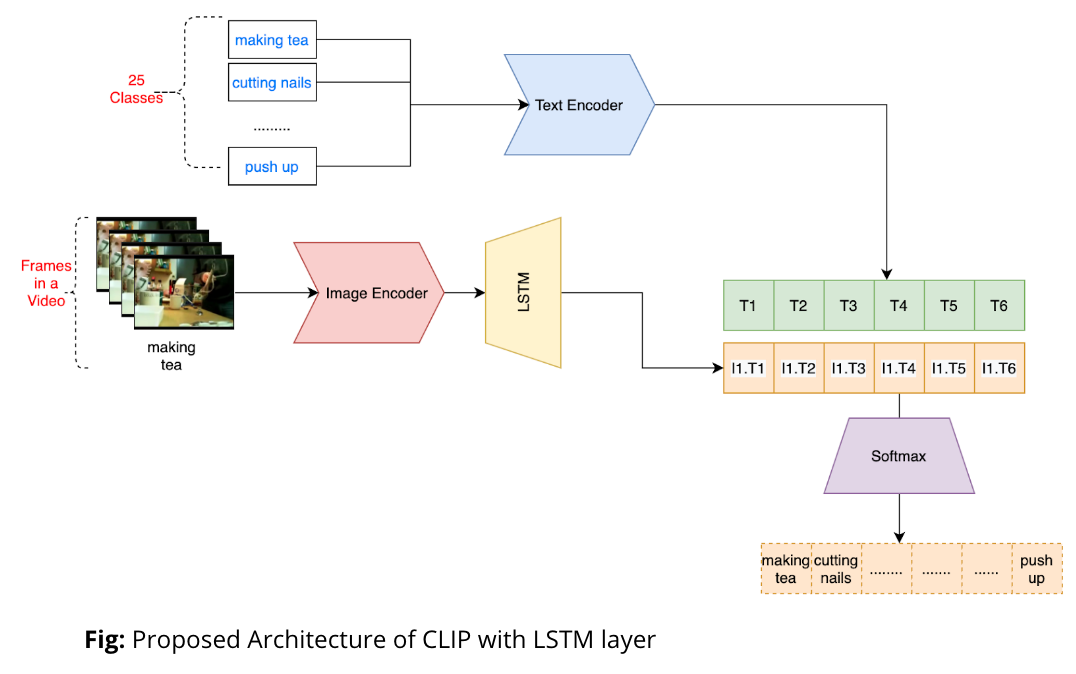
- In further experimentation, we want to project an entire video as an embedding in the joint embedding space.
- Towards this we used a LSTM module that takes in series of image embeddings from the video and projects into a single embedding in the joint embedding space of GPT-3.
- Dot product of textual embedding with visual embedding to get classification logits. Trained this on kinetics, and will show results in the upcoming slides.
Temproal fused using Transformer
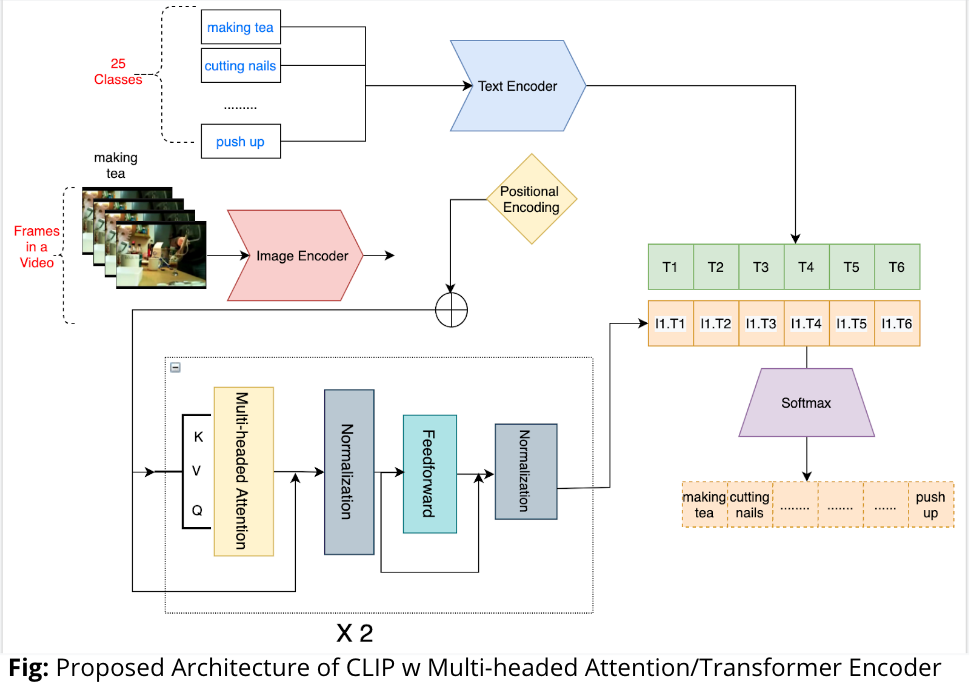
- We improved upon the previous approach by using a multi headed attention blocks to extract a visual embedding representing the input video.
Retrieval
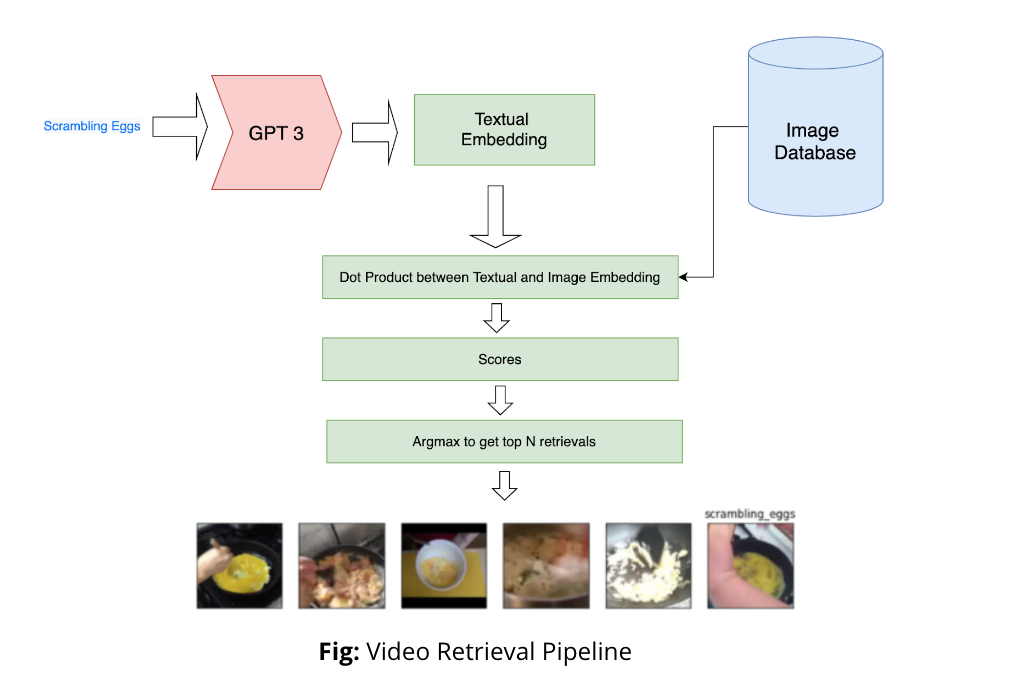
- Finally we remapped the video classification model for retrieval. Using this pipeline given any textual query we retrieve all the videos that match the textual query.
- To do this we use GPT-3 to first convert text query into an embedding.
- Then compute the visual embedding for all the videos in the database using our classification model.(This step only needs to be done once and can reused across queries).
- And use the dot product between the video embeddings and text embedding to get similarity score.
- And returns the samples with highest similarity, dot product score.
Results
-
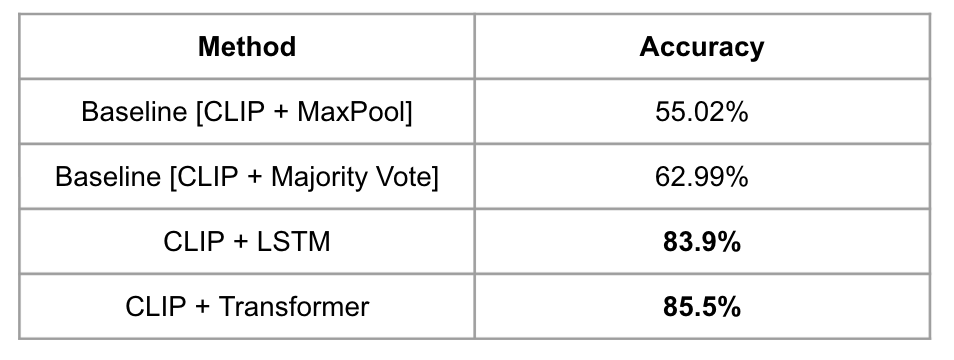
The first task towards Video Retrieval requires the best action recognition model. Thus, we tried four different extensions of Image based CLIP Model to work for action recognition on videos. For the baseline we did a maxpool over all the frames in a video, and used CLIP Architecture to give the top voted class. Another, baseline architecture is taking majority votes over all the frames in a video. This gave a performance of 55.02% and 62.99% respectively.
-
However, the above models did not take into account the temporal relationships between the frames in a video. We achieved that by adding LSTM/Transformer to the existing CLIP Architecture, which gave a performance of 83.9% and 85.5%. The increase in accuracy could be accounted for by the temporal relationship between the frames in the video, which was being ignored in the case of baseline architecture, as all the frames were treated individually.
- The original CLIP paper[1], takes a mid frame approach (taking middle frame in video and performing image-based classification on that) for action recognition and achieves an accuracy of only 53.4 percent.
- Thus, adding temporal information improved the performance on video action recognition by around 32 percent.
NOTE:
-
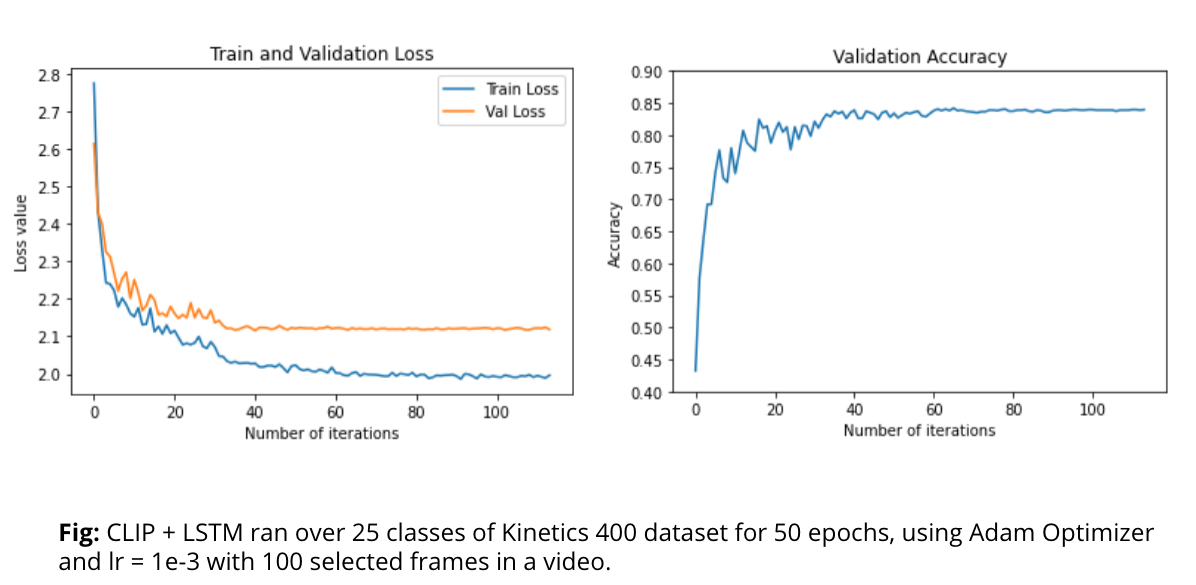
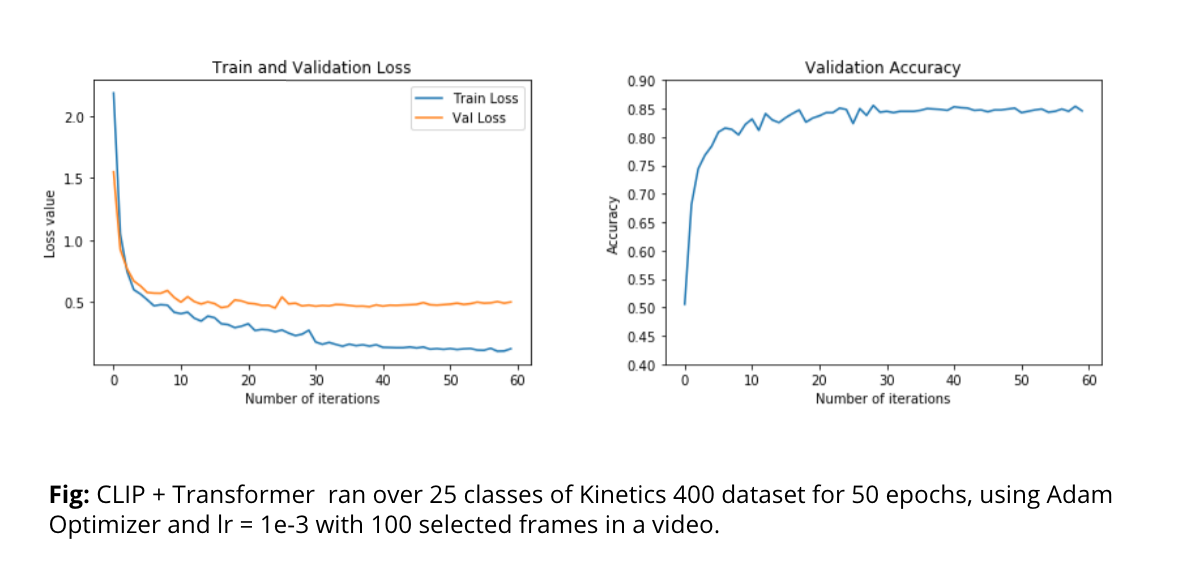
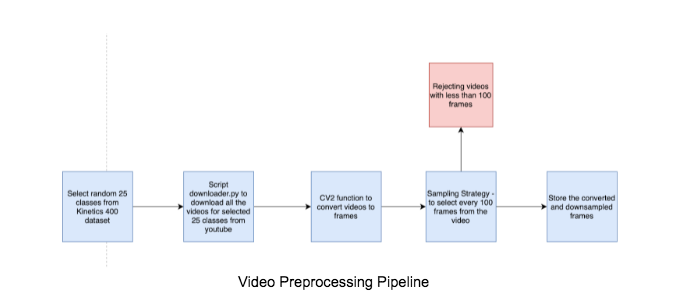
The above model has been tested on only 25 classes of kinetics400 dataset, due to limited resources available on AWS in terms of video storage, frame storage and training. Also, we downsampled the video 100 frames per video, which might also have reduced the performance. In future, we would keep video length as a hyperparameter too.
-
We can see the loss curve of training and validation loss. The loss curve indicates overfitting, and the possible reason could be less number of classes and examples in the train dataset. We see similar behavior in both CLIP + LSTM and CLIP + Transformer Architecture.
Action Recognition
Retrieval


Embeddings
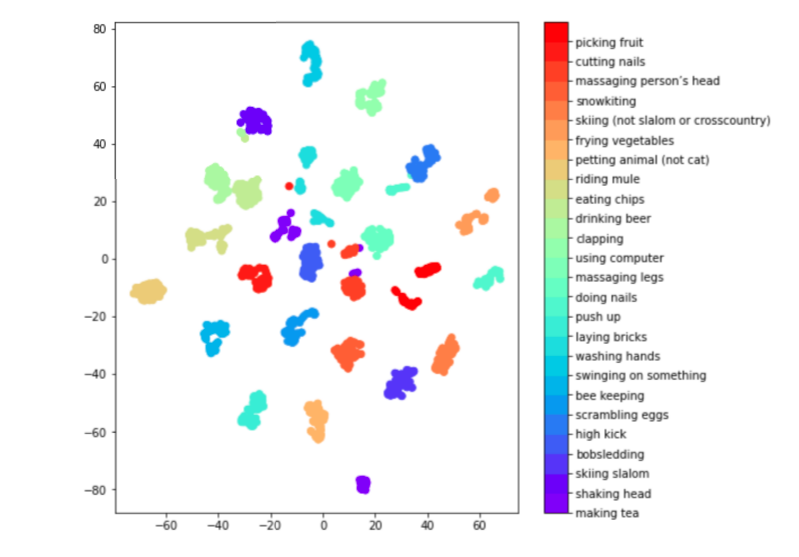
Conclusion
-
We extended the above trained models to Video Retrieval Task and got a remarkable result on image retrieval as indicated in the pictures. The way it works is that we calculate the text embedding of the entered query and get the embeddings of all the videos calculated using the above trained models (variations of CLIP) and get all the videos similar to the text embedding, by calculating the cosine similarity between text and video in the embedding space.
-
All the frames for a video cluster together as evident in the embedding space visualization (t-SNE - reduced from 1024 dimension to 2 dimension) of the video embedding corresponding to selected 25 classes.
-
The generalisation and performance of the model was done on two different datasets - Kinetics400 and VIRAT dataset as shown in Figures. Content Based Video Retrieval [egs: YouTube] is desirable because searches that rely purely on metadata are dependent on annotation quality and completeness. The presented architecture provides an efficient way of Text based Video Retrieval.
-
Also, our work is an extension of CLIP Model Action Recognition [RN50x16], where they have used Mid-frame level approach to get an accuracy of 53.4%, while our method gives an improvement of 83.9% [LSTM] and 85.5% [Transformer] comparing to the SOTA on Kinetics 400 dataset 84.8%.
Future work:
- Our current work is based on classifying an action over the entire video. Using the same LSTM /Transformer model, we also wish to caption/add subtitle to each frame in the video with changing action.
- For proof of concept, we have worked on 25 classes of Kinetics 400/700 dataset. In the future, we would be extending our work on the entire dataset with 400/700 classes.
- We wish to see the performance on other complex datasets like MSR Action 3D and datasets like RareAct which contain unusual actions like “hammering a phone” and “drilling an egg’’. This will give us true performance of all the model over unusual/unseen actions too, which will validate the generalization of the model.
- We also wish to explore the adversarial space of CLIP Models as different attacks like text patching and adversarial perturbation have been tried.
References
[1]Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal,Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, ArielHerbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M.Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, MateuszLitwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, AlecRadford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. 2020.
[2]J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-ScaleHierarchical Image Database. InCVPR09, 2009.
[3]Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks forvideo recognition, 2019.
[4]Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzy ́nska, SusanneWestphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag,Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The “something something”video database for learning and evaluating visual common sense, 2017.
[5]Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L. Berg, Mohit Bansal, and Jingjing Liu.Less is more: Clipbert for video-and-language learning via sparse sampling, 2021.
[6]Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar-wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and IlyaSutskever. Learning transferable visual models from natural language supervision, 2021.
[7]Motoki Sato, Jun Suzuki, Hiroyuki Shindo, and Yuji Matsumoto. Interpretable adversarialperturbation in input embedding space for text.arXiv preprint arXiv:1805.02917, 2018.
[8]Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, DeviParikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-basedlocalization, Oct 2019.
[9]Lucas Smaira, João Carreira, Eric Noland, Ellen Clancy, Amy Wu, and Andrew Zisserman. Ashort note on the kinetics-700-2020 human action dataset, 2020.[10]Pedro Tabacof and Eduardo Valle. Exploring the space of adversarial images. In2016 Interna-tional Joint Conference on Neural Networks (IJCNN), pages 426–433. IEEE, 2016.
[10]Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. “Learning transferable visual models from natural language supervision.” arXiv preprint arXiv:2103.00020 (2021).
[11] Xin Sun∗ , Chi Zhang∗ , Guosheng Lin, and Keck-Voon LING et al. “Open Set Recognition with Conditional Probabilistic Generative Models” arXiv:2008.05129v2 [cs.CV] 9 Feb 2021
[12] Martin Mundt, Sagnik Majumder, Iuliia Pliushch, Yong Won Hong, and Visvanathan Ramesh et al. “Unified Probabilistic Deep Continual Learning through Generative Replay and Open Set Recognition” arXiv:1905.12019v4 [cs.LG] 4 Sep 2020