
One-Shot Video Object Segmentation
2017, Dec 15
One Line Summary
- Semi supervised video object segmentation using the one shot approach, one of the state-of-the-art method on the davis dataset.
Motivation
- Most of the current literature on semi-supervised video object segmentation enforces temporal consistency in video sequences to propagate the initial mask into the following frames, there is a need for model with less computational complexity.
Detailed Summary
- FCN model is initialized with the pretrained imagenet weights, and then trained for the task of vos, this step is referred to as intial offline training, which is followed by the online training and testing.
Novelty and Contributions
- Does one shot learning, given a first frame image and the ground truth the predictions are estimated for the rest of the frames in the video
- Although all frames are processed independently, the results are temporally coherent and stable.
Network Details
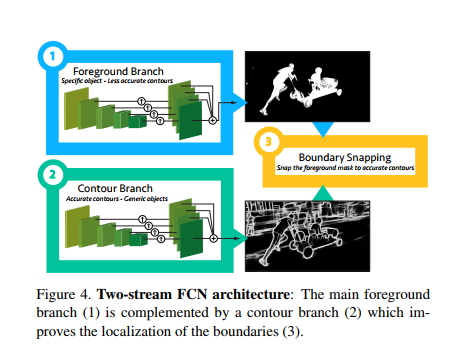
- Model is based on fully convolutional neural network architecture,
- Works in intial offline training followed by offline training and testing.
Results
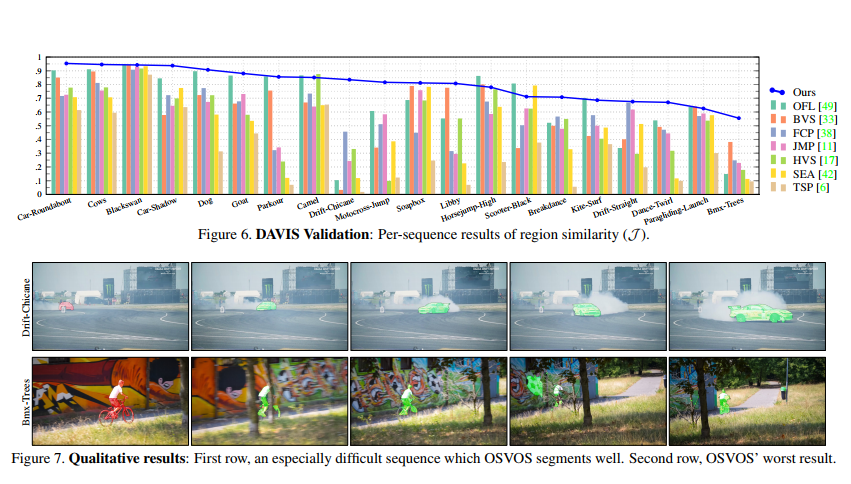
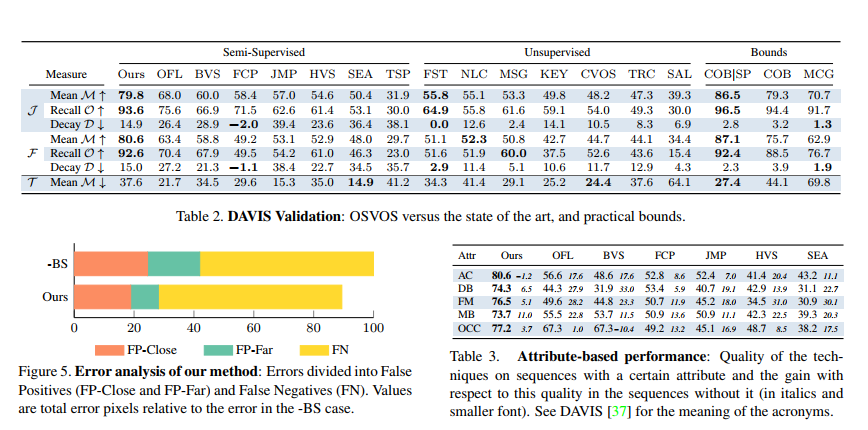
Authors
Sergi Caelles, Kevis-Kokitsi Maninis, Jordi Pont-Tuset, Laura Leal-Taixé, Daniel Cremers, Luc Van Gool