
MoCoGAN :Decomposing Motion and Content for Video Generation
2017, Dec 18
One Line Summary
- Generative Adversarial Network is used for decomposing the motion and content informaiton in the video, and the latent space walk is used for the video generation.
Motivation
- Motion and object information are inherently very less correlated, for example same object can have different motions, and different objects can have the same motion.
Detailed Summary
- The proposed framework generates a video by mapping a sequence of random vectors to a sequence of video frames. Each random vector consists of a content part and a motion part. While the content part is kept fixed, the motion part is realized as a stochastic process. To learn motion and content decomposition in an unsupervised manner, this paper introduces a novel adversarial learning scheme utilizing both image and video discriminators.
Novelty and Contributions
- Representing the motion as a path in the latent space rather than as a point, so that the videos of different length can be represented.
Network Details
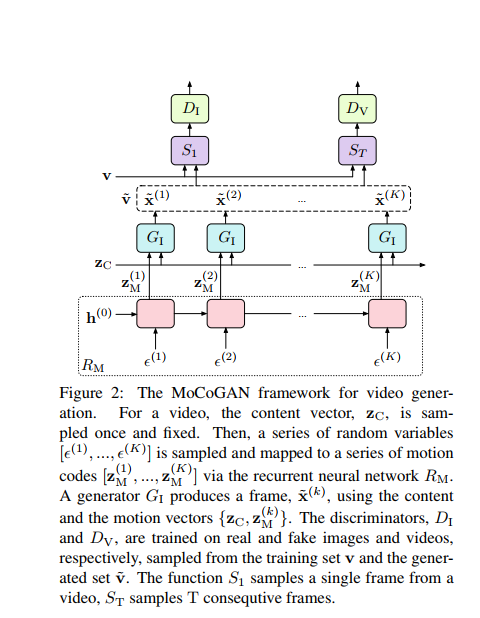
- LSTM based generative model that uses the encoded motion and the content information for the video generation

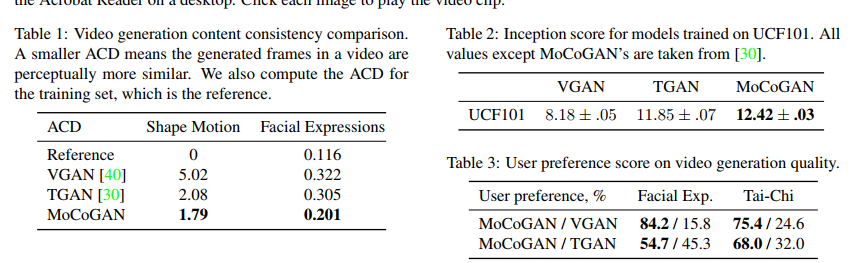
Results

Authors
Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, Jan Kautz