FusionSeg :Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos
2017, Dec 16
One Line Summary
- End-to-end learning framework for segmenting generic objects in videos using the appearance and motion information.
Motivation
- Motion and appearance information both provide the cues for video object segmentation, so fusion of both of the cues results in better predictions and more generalized results.
Detailed Summary
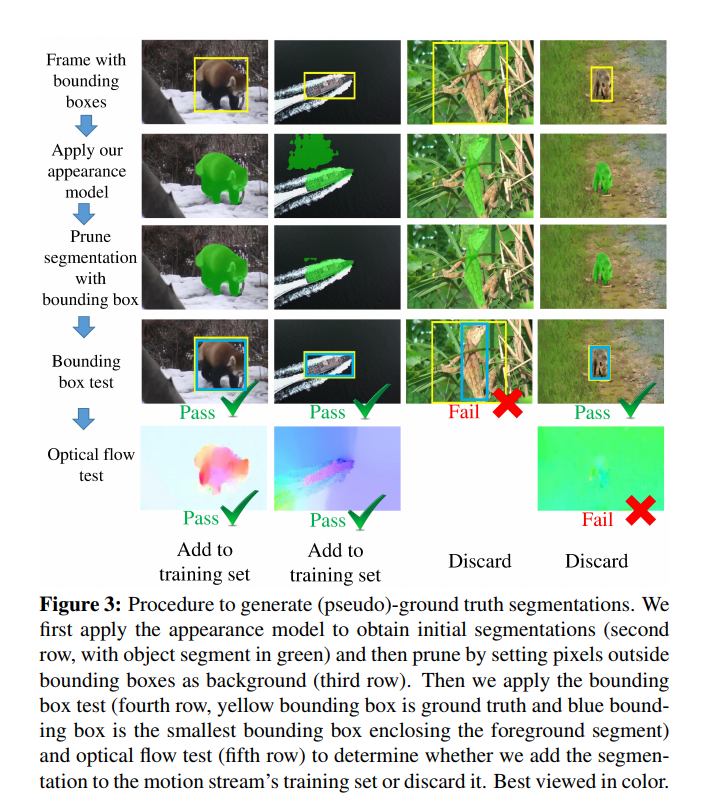
- Method learns to combine appearance and motion information to produce pixel level segmentation masks for all prominent objects.
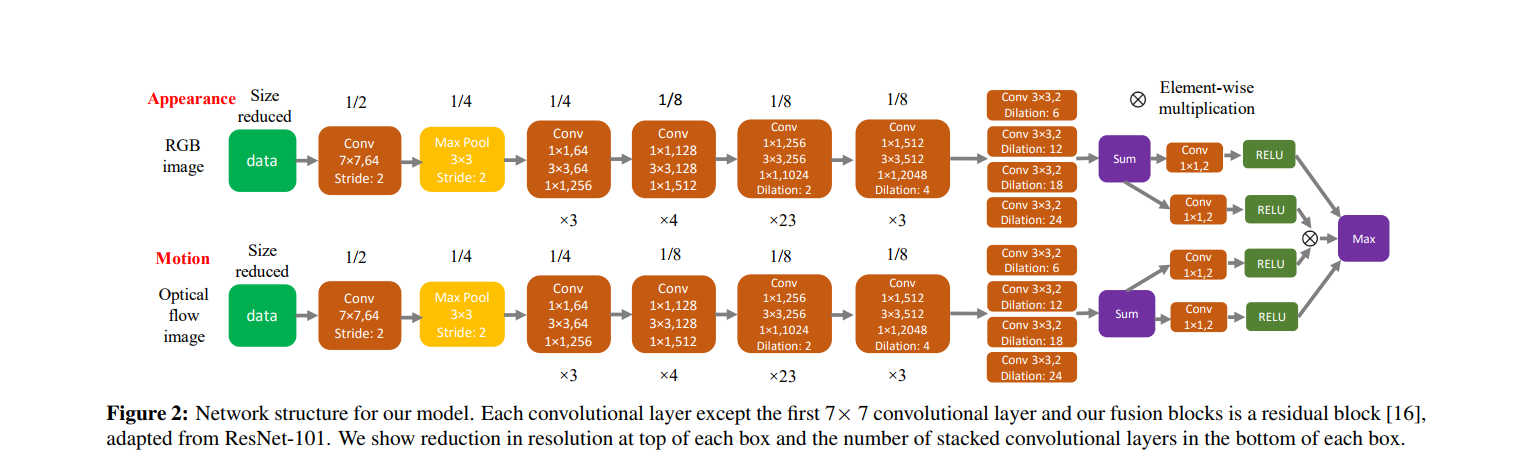
- A two-stream fully convolutional neural network which fuses together motion and appearance in a unified framework.
Novelty and Contributions
- Two-stream fully convolutional deep segmentation network where individual streams encode generic appearance and motion cues derived from a video frame and its corresponding optical flow
Network Details
- Fusion of the features from both apperance and motion giving the encoded representation that contain both the features.
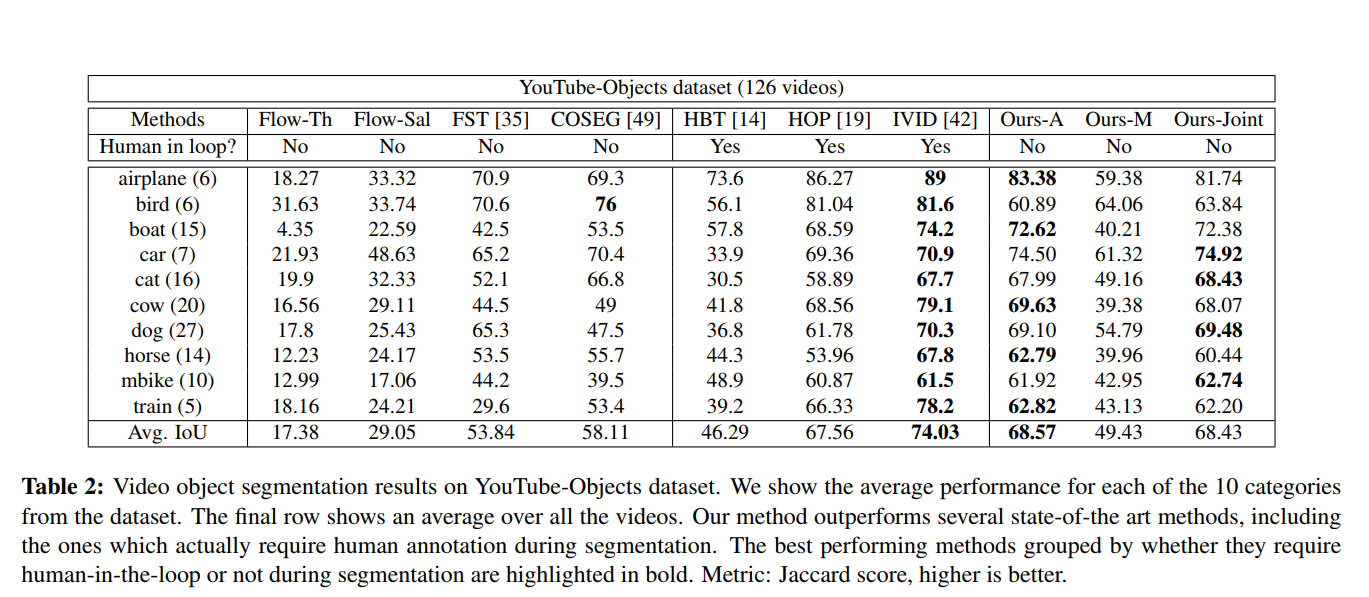
Results
Authors
Suyog Dutt Jain Bo Xiong Kristen Grauman